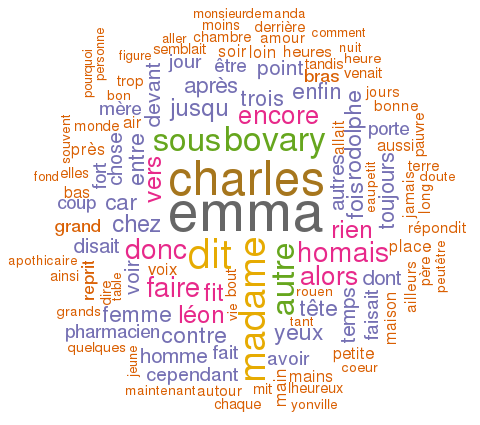
Un wordcloud avec R
Dans le cadre d'un cours de statistiques appliquées à la recherche du 1er semestre du master en science de l'information, on a touché un peu à R et un tout petit peu plus à RStudio, qui n'est qu'un IDE pour R, et comme je m'y étais déjà un peu intéressé, j'en ai profité pour aller voir plus loin. Plus loin, c'était peut-être plus près, comme toujours ça dépend des points de vue. Je me suis donc amusé à faire des wordclouds, ou des nuages de mots, afin d'en montrer la fréquence d'utilisation, à partir d'un "corpus", en l'occurrence le Madame Bovary de Flaubert.
Je me suis principalement basé sur ce tutoriel.
Installation
Pour l'installation de R, c'est assez simple et bien documenté. Je l'ai fait sur deux postes, l'un sous Fedora 20 avec un simple yum install r-base en root, l'autre sous Debian Wheezy, d'abord avec le même simple apt-get install r-base en root également, mais en fait j'ai constaté plus tard que la version des dépôts ne permet pas toujours d'installer les libraries voulue, donc il est préférable d'ajouter le dépôt C-RAN, comme indiqué là : http://cran.r-project.org/bin/linux/debian/README.html. Il manque juste l'info sur la clé publique du dépôt. Un gpg --keyserver subkeys.pgp.net --recv-key 381BA480 a bien fonctionné de mon côté.
Pour RStudio, il faut télécharger le paquet ad hoc, par exemple le rpm ou le deb et l'installer avec yum ou apt-get, ceci afin d'avoir bien toutes les dépendances. Du moins, c'est ce que j'ai constaté. Et c'est parti.
tm et wordcloud
La première chose à faire, c'est de se munir d'un corpus de texte(s), s'il(s) est (ou sont) en .txt, c'est mieux. Pour ma part, pour mon premier test, j'ai pensé à du Flaubert, va savoir pourquoi. Dans ce genre de situation, j'aime bien aller sur Project Gutenberg, parce qu'on y trouve des œuvres en format texte, et j'ai même trouvé Madame Bovary en français, assez facilement pour une fois. Je l'ai téléchargé, enregistré à quelque part. Je l'ai un brin "nettoyé" avec un éditeur de texte pour supprimer les infos ajoutées par le projet en anglais, avant et après le texte, ce qui a dû me prendre une minute.
On peut ouvrir RStudio et installer les libraries dont on a besoin : tm pour le text mining, wordcloud pour le wordcloud, si, si, je te jure, et en testant j'ai vu qu'il était utile d'installer aussi SnowballC pour faire du stemming. Plusieurs manière de le faire, soit avec les commandes, soit avec l'interface graphique de RStudio, ce qui revient quand même au même :
install.packages("tm")
install.packages("wordcloud")
install.packages("SnowballC")
Ce qui doit pouvoir se simplifier en install.packages(c("tm","wordcloud","SnowballC"). En passant par l'interface graphique, ça se passe dans la fenêtre en bas à droite, l'onglet Packages, bouton Install. Un fois les paquets installés, on peut se lancer dans le script lui-même.
On commence par charger les libraries nécessaires :
library ("tm")
library ("wordcloud")
library ("SnowballC")
Puis, on crée le corpus :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/", encoding = "UTF-8"), readerControl = list(reader=readPlain, language="fr"))
bovary est le nom que j'ai donné au corpus. Corpus est une commande qui crée un corpus à partir de textes. Le DirSource donne le chemin vers le dossier qui contient le ou les textes à intégrer dans le corpus. On voit que l'on peut préciser l'encodage des textes. Attention, tous les textes contenus dans le dossiers vont être traités... readerControl précise quel lecteur il faut utiliser et la langue. En réalité, la commande proposée par le tutoriel cité plus haut fonctionne tout aussi bien :
bovary <- Corpus(DirSource("~/informatique/R/wordcloud/tmp/")
Puis, il s'agit de préparer le textes en supprimant les espaces surnuméraires, les majuscules, les mots vides (stop words) et la ponctuation.
bovary <- tm_map(bovary, stripWhitespace)
bovary <- tm_map(bovary, content_transformer(tolower))
bovary <- tm_map(bovary, removeWords, c(stopwords("fr"), "comme", "tout", "plus", "deux", "bien", "quand", "quelque", "peu", "puis", "tous", "toute", "toutes", "oui", "non"))
bovary <- tm_map(bovary, removePunctuation)
Ce que j'ai remarqué, c'est qu'on obtient de meilleurs résultats en supprimant les mots vides avant d'enlever la pontctuation. Je me suis en effet retrouvé avec beaucoup de mots comme "jai" ou "cétait". Je pense que c'est aussi que la liste des mots vides doit être améliorée. Il ne serait pas inutile de regarder de plus près les possibilités de tm en langue française. Dans la commande removeWords, j'ai ajouter quelques mots qu'il m'a semblé utile de supprimer aussi. J'y suis arrivé en tâtonnant, ce qui n'est pas très rigoureux...
Enfin, on peut générer le wordcloud :
wordcloud(bovary, scale=c(3.5,0.35), max.words=120, random.order=FALSE, rot.per=0.35, use.r.layout=FALSE, colors=brewer.pal(8, "Dark2"))
Donc on applique la commande wordcloud sur le corpus traité. scale paramètre les tailles relatives des grandes lettres et des petites. J'ai dû pas mal jouer avec ce paramètre en supprimant des mots, sinon j'obtiens des erreurs, parce qu'il n'est pas possible d'afficher tous les mots. rot.per détermine le pourcentage de mots qui seront affichés verticalement. Le dernier argument correspond aux couleurs. On peut connaître la liste des palettes possibles avec la commande display.brewer.all().
Une fois le nuage généré, on peut l'exporter en format image. J'ai testé le SVG, mais le résultat n'est pas terrible, avec les mots qui se chevauchent. Je n'ai pas réussi à comprendre pourquoi. Mais en PNG, le résultat est relativement satisfaisant.