

Collect and disseminate information on fee-based Open Access publishing in Sweden
Récolter, traiter et publier les données sur le coût de publication en OA, principalement des données sur les APC... et le faire sur Github. :)

When it comes to metadata hunting, better bring your dog with!
Terrier is used to retrieve metadata of scholarly works from a variety of sources.
Des techniques afin de faciliter l'accès aux publications scientifiques, qui sont exposées par les archives ouvertes, par les machines. Il s'agit d'un effort d'harmonisation pour améliorer l'interopérabilité des différents institutional repositories.
Annonce du 2015-03-31 de la possibilité de lier un ORCID à un Swiss edu-ID.
A large number of Twitter users are bots. They can send spam, manipulate public opinion, and contaminate the Twitter API stream that underline so many research works. One of the major challenges of research on Twitter bots is the lack of ground truth data. Here we report our discovery of the Star Wars botnet with more than 350k bots. We show these bots were generated and centrally controlled by a botmaster. These bots exhibit a number of unique features, which reveal profound limitations of existing bot detection methods. Our work has significant implications for cybersecurity, not only because the size of the botnet is larger than those analysed before, but also because it has been well hidden since its creation in 2013. We argue that more research is needed to fully understand the potential security risks that a large, hidden botnet can pose to the Twitter environment, and research in general.
via https://twitter.com/dbarthjones/status/824328441369600000
Pourquoi et comment migrer ses publications de academia.eu vers zenodo.org.

Un entretien avec Eric Gartner de chez « The Getty » par Antoine au sujet de l'utilisation d'un générateur de site statique pour la publication numérique de contenus scientifiques, qui doivent pouvoir être durables, ce qui n'est pas forcément gagné dans le monde numérique. D'où le choix d'outils relativement simples, non propriétaires, et surtout qui permettent au moins un accès au texte brut.
La mise en œuvre de ce genre de processus risque d'apporter quelques améliorations bienvenues, ou à tout le moins une formalisation des processus dont on ne peut que bénéficier.
Getting off isn’t just necessary to protect yourself, it’s necessary to protect your friends and family too.
Voilà un mec assez réveillé, qui a d'abord conseillé Facebook notamment pour des raisons de marketing, qui se dit un jour qu'il va lire les conditions d'utilisation et qui conseille de quitter, proprement si possible, le réseau pour protéger la vie privée des autres.
via Claire Zuliani [dont les marges vaillent la peine, tant du point de vue du contenu que de celui du contenant.]
edit: framasoft a publié une traduction : https://framablog.org/2017/01/23/si-on-laissait-tomber-facebook/

Quand ajouter de la sécurité dans l'utilisation des cookies apporte l'avantage de pouvoir mieux filer les internautes.
Je le poste ici comme exemple d'interface de recherche, ou tout y est, avec un design bento box, mais pas seulement, vu qu'il est possible de filtrer a priori.
Merci à @Flor_Mu pour le signalement !

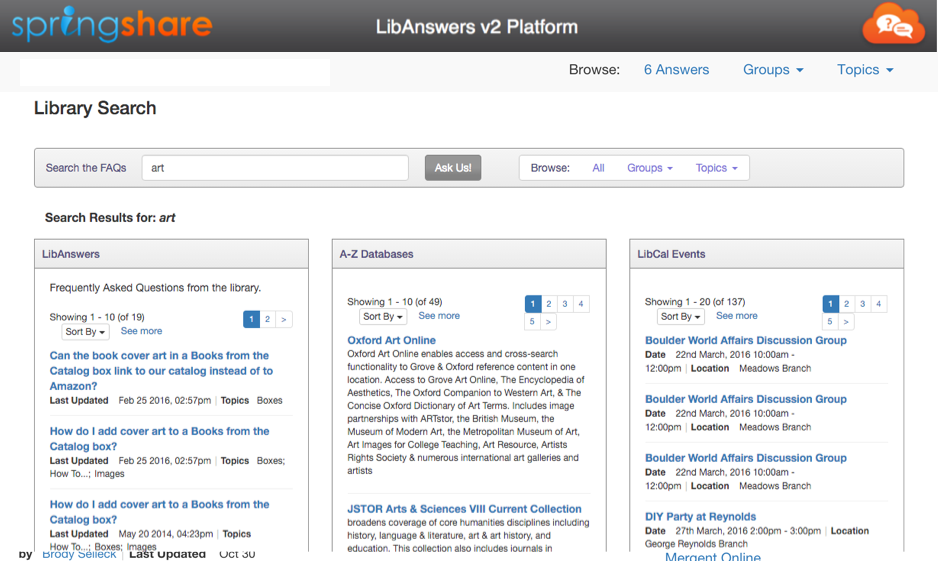
Provient de ce billet : http://blog.springshare.com/2016/03/22/libguides-2-1-12-update-unified-search-and-lti-updates-are-here/
Ce qui m'intéresse, c'est la diversité de objets retournés, classés dans des boîtes par catégories. Capture utile pour illustrer cette méthode de présentation de résultats de recherche, par exemple pour un portail de bibliothèque ou d'un outil de découverte

Un « framework » pour livre électronique. À explorer.
via @antoinentl : https://www.quaternum.net//2016/06/30/un-framework-pour-le-livre-numerique/

Un cas très intéressant de construction d'un modèle RDF pour un fonds d'archive, en lieu et place de la norme EAD, pour mieux décrire le fonds lui-même, et mieux le parcourir. Quelques passages intéressants:
Ce qui est fascinant avec le fonds Marker c’est que quel que soit le carton qu’on ouvre, les éléments nous rappellent d’autres éléments croisés plus tôt. A tel point qu’on pourrait s’y perdre (c’est d’ailleurs ce qui se passe régulièrement). Le rapprochement, c’est le principe qui semble organiser le fonds. Marker a réuni des éléments disparates dans des boîtes à chaussures, des cartons, des pochettes, autour d’un sujet, d’une ressemblance. C’est toute la dynamique qu’on retrouve dans sa bibliothèque, par un simple procédé d’insertion physique, souvent à la page près, deux éléments distincts sont connectés, un sens nouveau né de l’association se dégage. La richesse de la bibliothèque repose sur sa fragilité, si on sépare le document inséré de son ouvrage on perd la valeur produite par le rapprochement.
Chris Marker s’est passionné pour l’informatique dès les origines. De ses créations informatiques on peut citer le programme conversationnel Dialector écrit en Basic Apple Soft en 1985, ou encore le CD-ROM Immemory (1997). Une opération de sauvegarde est actuellement lancée sur 553 disquettes 5.25 pouces liées au programme Dialector. Plus largement, les archives numériques représentent 15 Terra-octet de données numériques natives. Ce gigantisme, difficilement traitable manuellement, constitue pour la Cinémathèque une invitation à élaborer des pistes de réflexion, concernant ce fonds mais également ceux à venir.
Le RDF permet de construire un vaste réseau tentaculaire et décentralisé, à la différence par exemple de l’XML-EAD au fonctionnement arborescent. J’ai choisi le RDF pour son adéquation directe entre l’objet à décrire et le modèle proposé pour le représenter. Car le fonds entier (la bibliothèque avec lui) est parcouru d’associations complexes, multicritères, et un plan de classement hiérarchisé et arborescent, même établi sur mesure, parviendrait difficilement à en décrire la richesse.
A la différence d’un système arborescent, le RDF permet de déplacer le regard, de rebondir, il autorise chaque utilisateur à emprunter un chemin différent, en fonction de ses intérêts. Quand on regarde le fonds d’un peu plus près on a l’impression d’observer un immense réseau multidirectionnel, cet proximité directe entre l’objet à décrire et son modèle s’est révélée assez fascinante.
MONNIER, Camille et N’DIAYE, Nola, 2016. Élaboration d’un modèle appuyé sur le RDF dans le cadre de la réalisation d’une Bibliothèque virtuelle Chris Marker à la Cinémathèque française. Chroniques chartistes [en ligne]. 22 décembre 2016. [Consulté le 8 janvier 2017]. Disponible à l’adresse : https://chartes.hypotheses.org/1442
via : @Daymonin

Lorsqu’une plateforme de blog montre des signes de faiblesse, c’est le bon moment pour s’interroger sur nos pratiques de publication et de présence sur le web, pour ne pas dépendre des services tiers et des silos : choisir ses outils, et suivre la formule magique POSSE, pour Publish (on your) Own Site, Syndicate Elsewhere, proposée par l’IndieWeb. En d’autres termes : réveillez les blogs !
Une réaction aux nouvelles venues de Medium, avec un exposé aussi clair que succinct sur les possibilités et stratégie de publication sur le web.

Un bon exemple de la difficulté de respecter les règles typographiques dans l'univers numérique actuel. Selon les règles de typographie en vigueur en Suisse romande, l'espace devant les ponctuations qui en prennent une, doit être insécable, certes, mais également fine. Or ce caractère unicode est encore peut supporté par les fontes de caractères et les navigateurs web. Du moins, c'est ce qui est prétendu dans cette issue du dépôt des styles csl pour Zotero.
Pourtant j'apprécierais d'avoir une version du style iso690 en français avec les espaces fines insécables et le support des petites majuscules pour les noms des auteurs.
Un bref historique et explication du Web sémantique, avec un point de vue différent de ce que j'ai l'habitude de lire.

GitLab Pages devient libre. Ouvre d'intéressantes perspectives.
Les 10 principes pour la protection des données de vos utilisateurs. Pourrait s'appliquer bien entendu aux bibliothèques et aux fournisseurs de logiciels ou de services pour les bibliothèques.
via https://twitter.com/jschneider/status/812360040082456576/photo/1

Le problème de l'insertion des couvertures de livres dans une interface de recherche de bibliothèque : si les images viennent d'un site tiers comme Amazon, alors ce dernier sait quel lecteur est à la recherche de quels livres. Sympa, non ?

Offre de SIGB en SaaS sur la base de Koha. Basé en Allemagne.