
Support de présentation d'une formation à la recherche dans la base de donnée bibliographique OpenAlex. Clair et précis.
Une brève histoire de la recherche d'information, depuis l'écriture à la recherche capturée par quelques acteurs assis sur quelques décennies d'accumulation primitive du capital et des données, et aussi quelques décennies de traitement automatique des langues naturelles.
Une série de vidéos en anglais, en accès libre, sur les revues systématiques.

Zotero Review Assistant is a Zotero plugin that aims to streamline the process of organizing articles for review research.
Permet d'attribuer un statut à une référence, une raison pour ce statut et de générer un diagramme PRISMA.

Un article sur une extension de navigateur (Chrome est supporté aussi, mais comme c'est un navigateur à éviter, il reste Firefox… ) qui permet de chercher dans son historique et ses onglets ouverts de manière efficace, entre autres choses.
via RSS, what else.
Une idée fort intéressante : implémenter une recherche full-text dans des livres électroniques. À garder en tête.

Un exemple (de plus, mais plus il y en a mieux c'est) de diffusion de la recherche en Open Access.

The FutureTDM project seeks to improve uptake of text and data mining (TDM) in the EU by actively engaging with stakeholders such as researchers, developers, publishers and SMEs.
BASE is one of the world's most voluminous search engines especially for academic web resources. BASE provides more than 100 million documents from more than 4,000 sources. You can access the full texts of about 60% of the indexed documents for free (Open Access). BASE is operated by Bielefeld University Library.
Powered by SolR and VuFind
découvert via : oadoi.org
Article Wikipedia, en anglais, sur la notion de CRIS. Système permettant la gestion de la recherche d'un ensemble donné (institution, nation, etc.).

Syntaxe de recherche de duckduckgo. Sans excessive surprise, mais c'est toujours utile de consulter l'aide pour être sûr...
Je le poste ici comme exemple d'interface de recherche, ou tout y est, avec un design bento box, mais pas seulement, vu qu'il est possible de filtrer a priori.
Merci à @Flor_Mu pour le signalement !

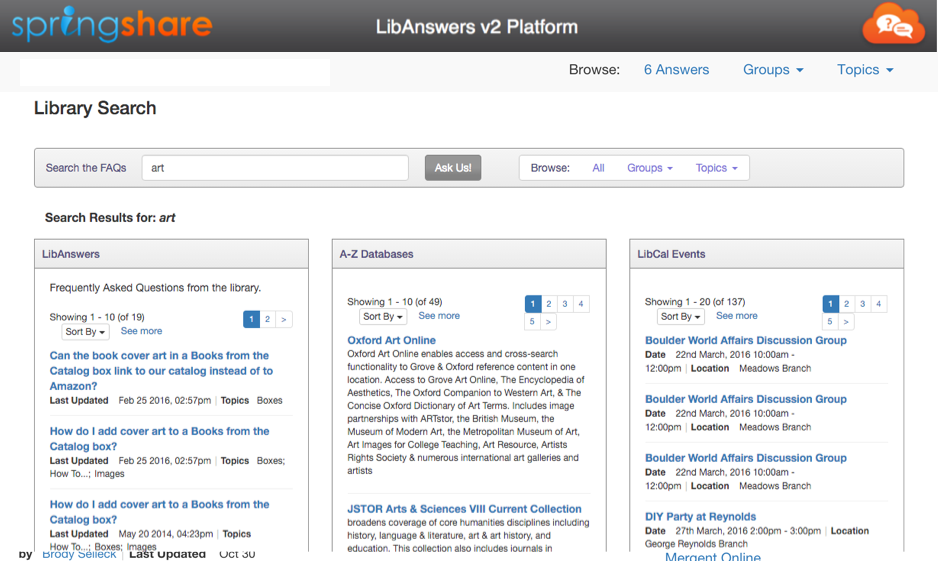
Provient de ce billet : http://blog.springshare.com/2016/03/22/libguides-2-1-12-update-unified-search-and-lti-updates-are-here/
Ce qui m'intéresse, c'est la diversité de objets retournés, classés dans des boîtes par catégories. Capture utile pour illustrer cette méthode de présentation de résultats de recherche, par exemple pour un portail de bibliothèque ou d'un outil de découverte
Système automatisé mutuel d’accès au réseau des catalogues d’articles et de notices documentaires échangeables
Réservoir des notices des bibliothèques publiques de la Belgique francophone. En mode FRBR selon Banfi, Elisa. 2016. Vers une optimisation du catalogue des Bibliothèques municipales de la Ville de Genève en vue des évolutions des formats et des plateformes catalographiques. Genève. (bientôt disponible sur doc.rero).

Utilisation de Word2Vec pour améliorer la recherche dans un corpus OCRisé dont la qualité laisse à désirer.
Comme le dit grolimour :
Mozilla Science Lab + Figshare + Github = DOI pour du code
On peut aussi passer par Zenodo : https://id-libre.org/shaarli/?mgX6Eg
Des modules de formation en ligne en compétence informationnelles, développées par l'Université de Genève (Bibliothèque).
Des vidéos sympathiques et un chouia impertinentes, avec un rappel textuel des points essentiels et des quizz pour s'auto-évaluer.
À disposition de chacun, possibilité de s'identifier pour la communauté académique de l'UNIGE. Peut être utilisé dans le cadre des formations des usagers par la bibliothèque ou dans le cadre de modules par les profs et les assistants.
La vidéo de lancement : https://mediaserver.unige.ch/play/95762

googleris a power tool to Google (Web & News) and Google Site Search from the command-line. It shows the title, URL and abstract for each result, which can be directly opened in a browser from the terminal. Results are fetched in pages (with page navigation). Supports sequential searches in a singlegooglerinstance.
googlerwas initially written to cater to headless servers without X. You can integrate it with a text-based browser. However, it has grown into a very handy and flexible utility that delivers much more. For example, fetch any number of results or start anywhere, limit search by any duration, define aliases to google search any number of websites, switch domains easily... all of this in a very clean interface without ads or stray URLs. The shell completion scripts make sure you don't need to remember any options.
googlerisn't affiliated to Google in any way.
Ça fait un moment que je cherche quelque chose dans le genre. Il y a bien surfraw, mais c'est quand même un peu mort comme projet.
via : https://www.zotero.org/groups/emerging_tech_in_libraries (et si les groupes Zotero étaient une source d'information riche ?)
Réaction à la volonté d'aboutir en 2020 à 100% des publications scientifiques en EU en Open Access. C'est bien mais pas suffisant. La part la plus importante de la recherche a lieu avant la publication. Et c'est aussi dans cet avant-là que l'ouverture et la liberté sont importantes pour que la science soit réellement ouverte.
Thèse défendue sur le terrain de la culture étudiée, afin que les personnes concernées puissent prendre connaissance des résultats de la recherche et de confronter les "vérités" et les "savoirs" entre le chercheur et les personnes concernées.